Recently I finished an app with complex Backbone.js-based interface. It resulted in hierarchy with 3 levels of hierarchy, with about 10 final classes. Here are a couple of ideas on how to manage this hierarchies and make it simpler.
A bit of fantasy
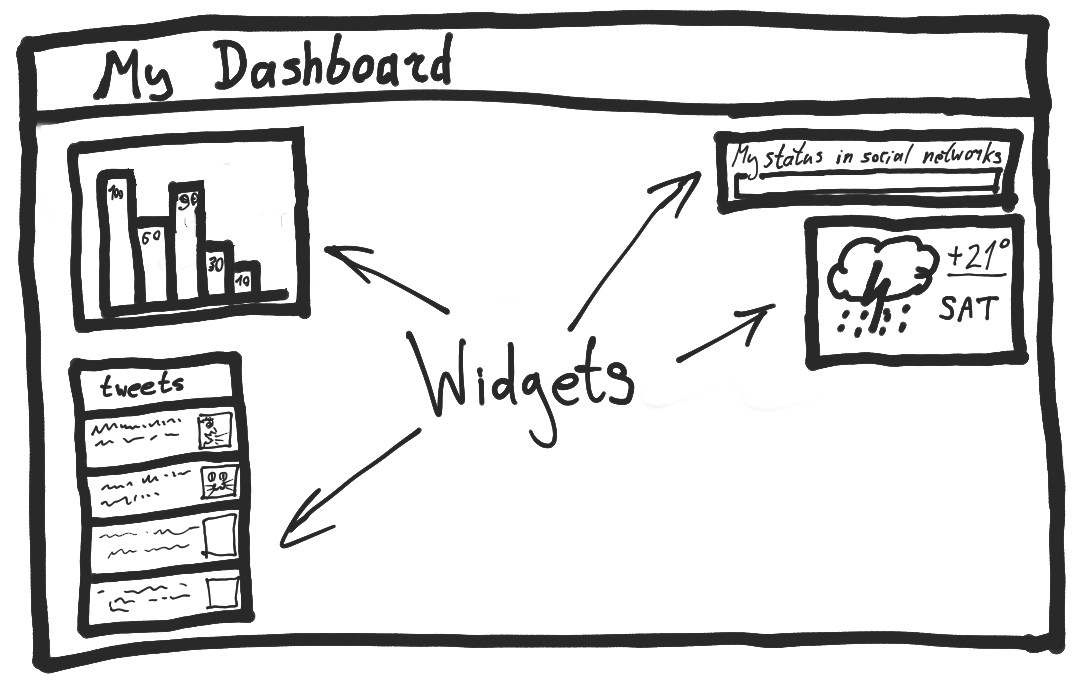
Let's describe an example app. I always wanted an universal dashboard for daily use. It could show statistics on communities I'm interested in, information on websites & servers I maintain, a weather report for the next weekend, filtered news, and so on. It also will provide some controls.
The goal is to get up in the morning, and check everything you need in 10 minutes.
Dashboard implementation
Our dashboard will be just a space, filled with widgets. Each widget shows a piece of information:
Each widget is an object. I'm using
backbone.js for interface implementation, and we won't dig into it's details, but we'll examine a simple OOP pattern done with Backbone. It gives us a base class named
Backbone.View, from which we inherit our widgets. Method, which displays a widget is called render():
(You can see a simple example of entire backbone.js app here)
App.views.Widget = Backbone.View.extend({
template: <...>,
render: function(){
// Show widget's DOM using model's data:
this.$el.html(this.template({model: this.model.attributes}));
},
});
Let's assume we already have an implementation of single widget, which fetches data from server, and shows the widget:
But our goal is multiple widgets, with different functionality!
What is common among all widgets?
- They are tied to corresponding Backbone models with data.
- They can be moved, hidden, deleted, their size can be changed. This means render()method will also add some common controls.
From now, common functionality requires that we create a widget's base class:
App.views.Widget = Backbone.View.extend({
template: <...>,
initialize: function(){
// redraw after model change
this.model.listenTo(this.model, 'change', this.render);
},
render: function(){
// Show widget's DOM, using model data:
this.$el.html(this.template({model: this.model.attributes}));
// Adding common controls:
...
},
});
What's the difference between widgets?
- One kind of widgets just shows data: a diagram or a picture.
- Another kind of widgets is used for making some actions. E.g. to change a status in all social networks. The most convenient way is WYSIWYG approach, i.e. we change an input field - and it's saved automatically. We may have multiple fields in single widget, e.g. we may want to change a "product-of-the-day" in our web store, and add a discount value. All these actions must be applied immediately.
- Third kind of widgets is realtime-updating, like Twitter timeline, messages from social networks or support services, forum monitoring. This is similar to 1st kind, but should update in real time, using comet approach, or websockets.

3rd kind example suggests that we don't know which requirements we'll need to implement tomorrow. We can implement everything using websockets at once, but let's assume we already implemented (1) using simple GET request by timer, and decided to add websockets later, when we already implemented a dozen of (1) and (2), and made some hierarchy... and new change in functionality will affect this hierarchy. More specific, we need to connect to websocket in
initialize() method:
App.views.RealtimeDiagramWidget = App.views.Widget.extend({
initialize: function(){
// Initialize base class:
App.views.Widget.prototype.initialize.apply(this, arguments);
// Subscribe to websocket:
App.websocket.on('graph-update', _.bind(function(){
// update Backbone model with widget's data:
this.fetch();
}, this));
},
});
Also we may wish to add new controls. So we need to redefine
render() method
:
App.views.RealtimeDiagramWidget = App.views.Widget.extend({
initialize: function(){
...
},
render: function(){
// Render base class:
App.views.Widget.prototype.render.apply(this, arguments);
// Add new, widget-specific controls:
...
},
});
We want to extend our application, but we don't know which functionality we'll need tomorrow. As we use Backbone, we'll need to change 2 methods:
render() &
initialize(), and change them in different ways.
Class hierarchy may become too tangled. Let's see:
- At 1st development iteration we implement base widget class, and few child classes with simple diagrams.
- 2nd iteration brings us editable widgets, which will automatically save values from their fields. We add a base class for them, named App.views.EditableWidget.
- At 3rd iteration we add a zoom function to some diagrams, which requires adding new controls showing on mouse over a widget, and also add realtime-updating widget named RealtimeDiagramWidget.
With each inheritance we wrap render() & initialize() functions inside corresponding functions of child class. This brings additional disadvantage: if we need to compose or filter our data, we need to pass them to render() function of the base class somehow. We can add arguments, which looks a bit ugly:
render: function(processedData) {
if (processedData === undefined) {
processedData = {};
}
var data = processedData;
data[model] = this.model.attributes;
this.$el.html(this.template(data));
}
Let's draw resulting connections with
blue and
green color on a diagram:
 Looks too complicated. Our mistake is that we don't need to redefine render()
Looks too complicated. Our mistake is that we don't need to redefine render() &
initialize() methods in each child class. The actual thing we need to do is to change their code in child class.
And here comes
Template method pattern.
Let's ditch
render() method's arguments and method redefinition. If we need to change the data, just add a
hook to get custom data:
render: function() {
var data = {}
// Add data from child class, if they're exist:
if (this._preRenderHook !== undefined) {
_.extend(data, this._preRenderHook());
}
// Old functionality:
data[model] = this.model.attributes;
this.$el.html(this.template(data));
}
If we need to add new controls - add a hook which adds new controls:
render: function() {
var data = {}
// Add data from child class, if they're exist:
if (this._preRenderHook !== undefined) {
_.extend(data, this._preRenderHook());
}
// Old functionality:
data[model] = this.model.attributes;
this.$el.html(this.template(data));
// Controls:
if (this._postRenderHook !== undefined) {
this._postRenderHook();
}
}
And so we get a hierarchy without complicated connections:
Obviously, in case of more complex hierarchy we'll want to redefine hooks in child classes to extend them, or to add hooks into hooks. But now we have advantage of plain structure. We also may implement a list of hooks, if needed.
The most interesting thing is that we don't think about child classes functionality when we build base class. When we define a new type of widget, we just add hooks we needed to the base class' hook list. We don't need to worry about hierarchy level.
Classical
Template method pattern pattern assumes that base algorithm is already defined. But here we have a simplified kind of algorithm in a base class, which just represents order of execution of it's parts. And we can simply skip those parts if we don't need them.
Profits of such approach:
- We can add hooks quickly, at each stage of development. They won't affect classes which are already defined.
- We can put hooks in any place of base class, not only augment it at the beginning and end, as it happens in case of redefinition. If we have too many hooks, it can complicate method's control flow, but we still may tweak order of hooks invocation - which is widget's parts initialization order.
- Code structure is plain. Methods are not put into each other, instead they're just added to the base class' structure. This is much simpler to read and work with.
Example of execution flow of
render() method; "+" is where we add new hooks: